



Wprowadzenie
GraphQL to język zapytań (query language) dla API, który został opracowany przez Facebook i społeczność. Swoja premierę miał w czerwcu 2018. Obecnie jest to już dojrzała technologia, która zyskała uznanie na rynku. W związku z tym jest ona dobrze rozpoznawalna i wiele firm decyduje się na jej wdrożenie.
Czego się dowiesz?
W tym artykule wskażę Ci zasadnicze różnice pomiędzy architekturą REST a GraphQL. W kolejnych etapach przybliżę zasady posługiwania się tym językiem, co zbuduje nam świetny grunt do tego, aby zrealizować kilka przykładów nadających szersze spojrzenie na to jak wygląda ta technologia.
Cechy GraphQL
GraphQL jest często wymieniany jako następca REST API. Wynika to z tego, że rozwiązuje jego kluczowe problemy.
Jednak charakterystycznym podobieństwem dla tych obu rozwiązań jest niezależność od platformy czy języka programowania. Kolejną cechą wspólną jest idempotentność tych samych operacji. Zarówno dla architektury REST jak i dla GraphQL działania takie jak pobieranie, modyfikowanie, usuwanie umożliwia ich wielokrotne stosowanie bez zmiany wyniku.
Jest też wiele elementów charakteryzujących GraphQL, które czynią go coraz bardziej popularnym rozwiązaniem. Kluczową cechą GraphQL jest możliwość wykonywania elastycznych zapytań w ramach których sami definiujemy jakiej odpowiedzi z API oczekujemy. Dodatkowo język ten stwarza możliwość tworzenia wielu zapytań jednocześnie, co sprawa że w tych obszarach zyskuje on przewagę nad REST API.
Przykład
Rozpatrzmy przypadek, gdzie chcemy pobrać 10 najnowszych filmów z serwisu YouTube. W odpowiedzi spodziewamy się również informacji na temat autorów i metadanych na temat każdego odcinka.
W klasycznym podejściu reprezentowanym przez REST API należy wykonać najpierw zapytania o 10 najnowszych filmów. Wówczas dysponując kluczem (id) nowych filmów wykonywane jest zapytanie o ich autorów a kolejne do pobrania szczegółów na temat każdego filmu.
Dla kontrastu w przypadku wykorzystania GraphQL wystarczy wykonanie tylko jednego żądania. Dlatego ten przykład dobrze obrazuje moc jaką dostarcza GraphQL. Unikamy wykonywania serii zapytań, na rzecz prostego, precyzyjnego sposobu absorbowania danych. W związku z tym przekłada się to na wydajność aplikacji a także znacznie mniejszy ruch sieciowy.
Dostęp do zasobu
W przypadku podejścia tworzenia aplikacji RESTful, to dostęp do zasobu jest definiowany na podstawie rzeczowników, które są odzwierciedlenie obiektów w kodzie aplikacji. W zależności od zasobu jaki chcemy uzyskać należy wskazać odpowiedni adres przy uwzględnieniu właściwej metody HTTP. Twórcy GraphQL postanowili uprościć to podejście umożliwiając pobrać każdy zasób w ramach jednego, stałego adresu. Co sprawia, że spada poziom skomplikowania korzystania z takiego API, oraz trudność implementowania aplikacji klienckich dla tego rodzaju API.
Trzy kluczowe zasady GraphQL
Omawiany język zapytań bazuje na trzech zasadniczych filarach, które stanowią podstawę do jego wykorzystania. Do poszczególnych elementów należą:
1. queries i mutation
Komunikacja w GraphQL polega na wykonywania zapytań. Zapytanie jest tworzone z wykorzystaniem słowa query, przy uwzględnieniu właściwości zasobu. Odpowiedz na zdefiniowane żądanie jest przesyłane w formacie JSON, który ma analogiczną budowę do żądania, wzbogaconą o dane.
Istnieją dwa rodzaje żądań:
- query – do standardowego pobierania zasobów
- mutation – służące do wykonywania operacji modyfikujących np. dodawanie, usuwanie.
Przykład żądania
Poniższy fragment kodu demonstruje przykład wykorzystania query. Co zgodnie z jego definicją jasno wskazuje, że będzie on wykorzystywany do wykonywania operacji pobierania danych.
Kolejne elementy, które zawiera żądanie w tym przypadku to zapytanie o wideo z limitem 5 odpowiedzi. W ramach każdego wideo będą pobierane tylko informacje na temat id, type, name.
query {
video(count: 5)
{
id,
type,
name
}
}
W tym przykładzie zapytanie zostało oparte o 3 dane dla każdego wideo. Jednak można to uelastycznić dopisując kolejne atrybuty np. year, lub też zastosować ograniczenie i pobrać tylko po jednym atrybucie np. id.
2. Resolver
Jest to mechanizm, którego zadaniem jest określane miejsca oraz sposobu pobierania danych. Aby GraphQL mógł wiedzieć skąd ma czerpać zasoby należy mu to wskazać właśnie z wykorzystaniem resolverów. Istnieje wiele implementacji Resolverów, natomiast tworzenie aplikacji wystawiającej API najczęściej sprowadza się do wykorzystania jednej z nich i określenie interfejsu opisującego jak schemat danych dla odpowiedzi musi zostać uzupełniony.
3. Schema
Opisuje strukturę. Określa ona strukturę w jaki sposób będzie przedstawiana dana odpowiedź, czyli zwracany JSON. Schema opisuje przechowywane typy oraz to jak będziemy te dane przekazywać.
W ramach GraphQL jest kilka typów jakimi można się posługiwać:
- ID – klucz
- Int – zmienna typu całkowitego
- Float – zmienna zmiennoprzecinkowa
- String – łańcuch znaków
- Boolean – wartość logiczna
Dodatkowo przy każdym typie może być stosowany operator „!”, który wskazuje, że dany typ posiada stereotyp not null. Jasno on sygnalizuje, że dana zmienna nie może być wartością pustą.
Piaskownica
Istnieje wiele narzędzi, które pomagają w pełni zrozumieniu usług nowoczesnego budowania API. Najlepszym sposobem jest wykorzystanie klienta GraphQL. Jednym z najpopularniejszych klientów usług webowych jest Postman, który ma już pełne wsparcie dla tej technologii. Jednak na samym początku warto przyjrzeć się narzędziu, które można wykorzystać w ramach przeglądarki internetowej i jest dedykowanym rozwiązaniem do poznania GraphQL.
Narzędzie to nazywa się graphql-playground, które jest projektem o otwartym kodzie źródłowym. Umożliwia on naukę stawiania pierwszych kroków w ramach GraphQL. Projekt ten jest dostępny pod adresem:
https://graphqlbin.com/v2/6RQ6TM
Możliwe jest również pobranie wersji do uruchomienia na maszynie lokalnej. Piaskownica to baza danych filmów, która dostarcza API za pośrednictwem GraphQL. Jest w niej dostępny edytor, pełna dokumentacja, oraz możliwość wykonywania zapytań, co czyni z tego narzędzia niezastąpiony poligon każdego adepta tej technologii.
Interfejs piaskownicy wygląda następująco:
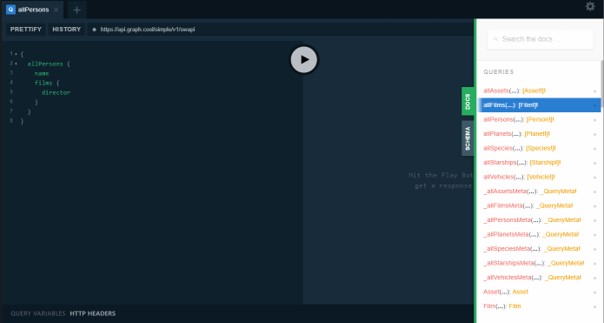
Już na początku widać pod jaki adres będą kierowane tworzone zapytania. Warto zauważyć, że ten adres się nie zmienia. Tak jak wspominałem jest to klasyczna cecha tego podejścia technologicznego.
Przykłady użycia
Na wstępie edytor posiada predefiniowane, przykładowe żądanie, które można wykonać. Wygląda ono następująco:
{
allPersons {
name
films {
director
}
}
}
Dokumentacja zawiera szczegółowe informacje na temat informacji każdego z atrybutów.
Rozpatrzmy ten przykład. Odwołuje się on do wszystkich osób znajdujących się we filmowej bazie danych. Od osób tych pobieranych jest imię (name), oraz powiązane filmy z ta osobą. Jednak z powiązanych filmów pobieramy tylko informacje na temat dyrektora produkcji (director). Na potrzeby zmniejszenia objętości treści artykułu postanowiłem zmodyfikować zapytanie, aby zwróciło tylko i wyłącznie jeden rekord:
{
allPersons(first: 1) {
name
films {
director
}
}
}
{
"data": {
"allPersons": [
{
"name": "Luke Skywalker",
"films": [
{
"director": "George Lucas"
},
{
"director": "George Lucas"
},
{
"director": "George Lucas"
},
{
"director": "Richard Marquand"
},
{
"director": "Irvin Kershner"
},
{
"director": "J. J. Abrams"
}
]
}
]
}
}
Warto zauważyć, że w tym przykładzie nie zaistniało żadne słowo kluczowe query czy mutation o którym mówiłem na początku wyjaśniania zasad dotyczących GraphQL. Jest to rezultat wykorzystania składni skróconej. Zawsze zaleca się dodawać typ zapytania (query lub mutation), a także jego nazwę, którą można wykorzystywać w ramach bardziej rozbudowanych zapytań.
W drugim przykładzie rozbudujemy żądanie w taki sposób, abyśmy mogli pobrać dodatkowe informacje. Niech to będzie poszerzony zbiór informacji zawierających wzrost, koloru oczu, a także filmów w jakich wystąpił dany bohater. Dodatkowo pytając o filmy, możemy dopytać na jakiej planecie akcja filmu się toczyła. W ramach każdego zapytania można zastosować ogranicznik, pobieranie elementów w określonej kolejności, sortowanie i podobne operacje. Takie opracowane zapytanie będzie miało następującą strukturę:
query ActorsWithFilmsAndPlanets {
allPersons(first:1) {
name
height
eyeColor
films (first:2) {
title
planets{
name
}
}
}
}
Rezultat odpowiedzi wygląda w następujący sposób:
{
"data": {
"allPersons": [
{
"name": "Luke Skywalker",
"height": 172,
"eyeColor": [
"BLUE"
],
"films": [
{
"title": "A New Hope",
"planets": [
{
"name": "Yavin IV"
},
{
"name": "Hoth"
},
{
"name": "Tatooine"
}
]
},
{
"title": "Attack of the Clones",
"planets": [
{
"name": "Naboo"
},
{
"name": "Coruscant"
},
{
"name": "Kamino"
},
{
"name": "Geonosis"
},
{
"name": "Tatooine"
}
]
}
]
}
]
}
}
Jak widać wykonywane operacje są w pełni elastyczne, możemy wykonywać dowolne zapytania, również łączone i dodatkowo parametryzowane, które mają wpływ na reprezentacje odpowiedzi. Dlatego te cechy najlepiej obrazują plastyczność tego rozwiązania.
Ostatnim przykładem będzie wykonanie operacji dodawania nowego filmu. W takim przypadku należy wykorzystać słowo kluczowe mutation. W następnej kolejności trzeba się odwołać do metody odpowiadającej za dodawanie filmu. W ramach tej metody koniecznie jest uzupełnienie wszystkich pól, które są wymagane.

Zgodnie z dokumentacją podaną na stronie można zauważyć, że należą do nich pola: episodeId, producers, charactersIds, planetsIds, speciesIds, starshipsIds, vehiclesIds. Dlatego przykład żądania będzie wyglądał w następujący sposób:
mutation CreateFilm {
createFilm(
title: "my film"
producers: "bykowski"
episodeId: 2
charactersIds: 1
planetsIds: 1
speciesIds: 1
starshipsIds: 1
vehiclesIds:1
)
{
id
}
}
Dalsze kroki
Wiele API jest przepisywanych z REST na GraphQL. Jednym z ciekawszych projektów w ramach którego można szerzyć swoje doświadczenia z GraphQL jest Spotify API, które właśnie korzysta z technologii opisywanej w artykule. Bezpośredni dostęp jest dostępny pod linkiem:
https://spotify-graphql-server.herokuapp.com
Jeśli interesuje Cię jak można samodzielnie zaimplementować GraphQL API z wykorzystaniem Java i Spring Boot, to zapraszam Cię do mojego materiału wideo, w którym live-coduje przykład zastosowania:
Podsumowanie GraphQL
GraphQL rzuca nowe światło na podejście tworzenia usług sieciowych, które udostępniają API. Swoimi elastycznymi formułami sprawia, że jest dużo dynamiczniejszy i bardziej intuicyjnych niż REST. Stały endpoint czyni z aplikacji dużo mniej skomplikowaną, a dokumentacja nie odgrywa aż tak niezbędnej roli. Na ogromny plus zasługuje wykonanie w ramach jednego żądania wielu podzapytań co przekłada się na większą wydajność, oraz zmniejszenie ruchu sieciowego. Jednak REST ma na tyle ugruntowaną pozycje, która praktycznie jest tradycją każdej usługi sieciowej, dlatego też GraphQL mimo swoich ogromnych zalet może mieć problem w przebiciu się przez rynek.

